前言
Fluentd是什么
Fluentd是一个开源数据采集工具,它可以让你统一采集和消费数据,以便更好地利用和理解数据。
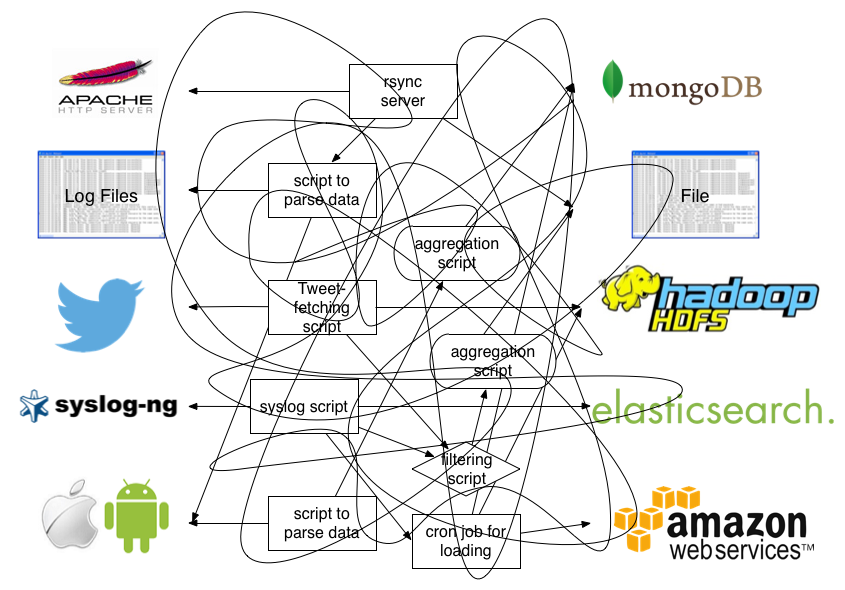
Fluentd处理前的数据
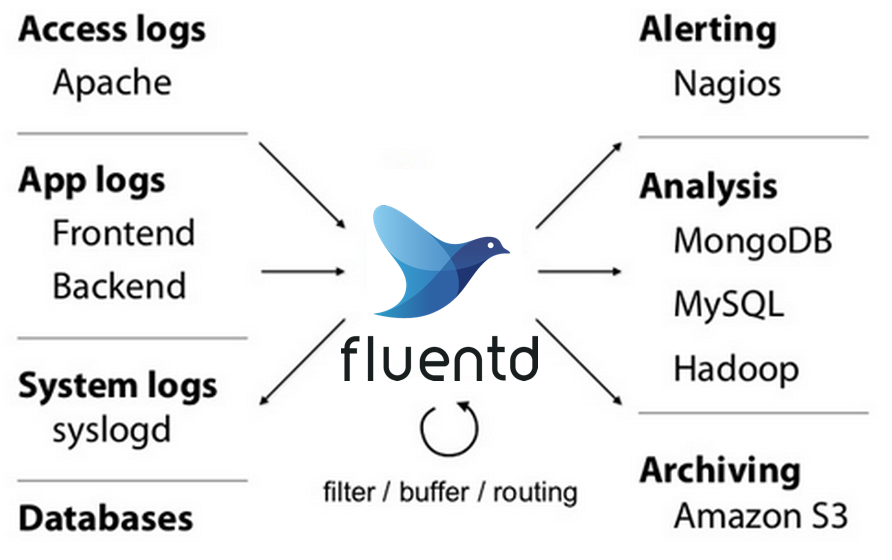
Fluentd处理后的数据
2. Fluentd的几个主要的特性
使用JSON统一日志结构(Unified Logging with JSON)
Fluentd尝试尽可能地将数据结构化为JSON,这个特点使得Fluentd能够统一处理日志数据的所有方面:在多个源和目标上采集、过滤、缓存、输出日志文件(统一的日志层)。使用JSON后,下游的数据处理起来相当的容易,因为JSON结构在保留了灵活的模式的同时,可以被无障碍的使用。
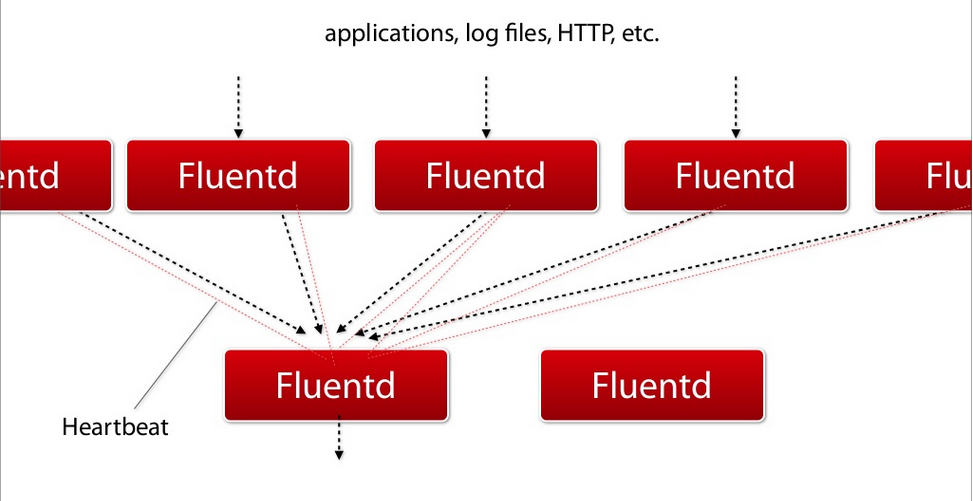
可插拔的架构(Pluggable Architecture)
Fluentd有一个灵活的插件系统,允许插件扩展其功能。拥有300+的社区贡献的插件来来实现几十种数据源和数据输出。通过利用插件,你可以马上开始使用您的日志。
最低的资源需求(Minimum Resources Required)
Fluentd是用C和Ruby组合编写的,需求非常少的系统资源。普通的实例内存占用在30-40MB,可以处理13000个事件/每秒/每核心。
高可靠性(Built-in Reliability)
Fluentd支持基于内存和基于文件的缓冲区来避免内部节点的数据丢失。Fluentd还支持容错和设置高可用。2000多家数据驱动的公司采用利用Fluentd来使用和分析他们的日志数据来区分他们的产品和服务。
为什么要用Fluentd
统一的日志处理层(Unified Logging Layer)
Fluentd从后台系统之间通过提供统一的日志记录层来解耦各个数据源。
此层允许开发人员和数据分析人员在生成日志时使用多种类型的日志。同样重要的是,它降低了脏数据给大家带来的风险。
一个统一的日志记录层让你和你的组织更好的利用数据,更快地在您的软件上进行迭代。
简单、容易、灵活(Simple and Easy yet Flexible)
Fluentd可以在不到10分钟内在笔记本电脑上安装好,您可以马上下载并尝试一下。Fluentd的300多个插件使它与数十个数据源和数据输出兼容。插件也是很容易编写和部署的。
开源(Open Source)
Fluentd是Apache 2.0许可的,完全开放的源代码软件。这意味着你可以不受任何限制的使用Fluentd和发挥Fluentd的极限。源代码在GitHub上可以下载:
https://github.com/fluent/fluentd/
经过印证的可靠性和性能(Proven Reliability and Performance)
2000多家数据驱动的公司利用Fluentd来更好的使用和解析他们的日志数据以区分其产品和服务。
一些Fluentd用户实时从数千台计算机收集数据。由于其只占用很小的内存(30~40MB),您可以节省大量的内存。
社区支持(Community)
Fluentd背后的社区不断改进软件,并帮助彼此使Fluentd对每个人都有用。
Treasure Data公司通过包维护和社区管理为Fluentd提供商业支持。
4. 说明
本文档基于Fluentd官方文档0.12版本翻译完成,如有误差,请以官方文档为准: